Data and Probability
Statistics
Statistics is the science of collecting, analyzing, and interpreting data to answer questions and make decisions in the face of uncertainty. Since statistical reasoning is now involved throughout the work of science, engineering, business, government, and everyday life, it has become an important strand in the school and college curriculum.
Understanding variability, the way data vary, is at the heart of statistical reasoning. Variation is understood in terms of the context of a problem because data are numbers with a context. There are several aspects of variability to consider, including noticing and acknowledging, describing and representing, and identifying ways to reduce, eliminate or explain patterns of variation.
Three Units of CMP3 address the Common Core State Standards for Mathematics (CCSSM) for statistics: Data About Us (Grade 6), Samples and Populations (Grade 7), and Thinking with Mathematical Models (Grade 8). The over arching goal of these Units is to develop student understanding and skill in conducting statistical investigations. A typical statistical investigation involves four phases:
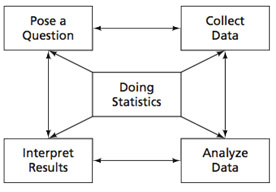
- Posing a statistical question
- Collecting relevant data
- Analyzing the distribution(s)
- Interpreting the results in light of the question asked
A statistical investigation is a dynamic process that often involves moving back and forth among the four interconnected phases. For example, initial data collection and analysis might suggest refining the question and gathering additional data. Work at any stage might suggest change in representations or analyses of the data before presentation of results. Below is a visual of this dynamic process.
Posing Questions
The question asked impacts the rest of the process of statistical investigation. A statistical question anticipates an answer based on data that vary versus a deterministic answer. Questions may be classified as summary, comparison, or relationship questions.
Summary questions focus on descriptions of data and are usually about a single data set. Examples: What is your favorite kind of pet? How many pets do you have?
Comparison questions involve comparing two or more sets of data across a common attribute. Examples: How much taller is a sixth-grade student than a second-grade student?
Relationship questions are posed for looking at the interrelationship between two paired numerical attributes or between two categorical attributes. Examples: Are students with after-school jobs more likely to have late or missing homework than students with no such jobs?
Collecting Data
In Data About Us and Samples and Populations students collect one-variable (univariate) data. In Mathematical Models students collect two-variable (bivariate) data. The data collected, and the purpose for their use, influence subsequent phases of the statistical investigation.
The concepts of numerical and categorical data are introduced in the Grade 6 Unit, Data About Us. Different questions elicit different types of data; we might ask questions that elicit numerical answers, or questions that elicit non numerical answers.
Examples of numerical data
We can collect data about household size and organize them by frequencies in a line plot showing how many households have one person, two people, and so on. We can collect data about student heights and organize them by intervals of 4 inches in a histogram by using frequencies of heights from 40 to 44 inches tall, and so on.
Examples of categorical data
We can collect data about birth years and organize them by using frequencies of how many people were born in 1980, 1981, 1982, and so on. We can collect data about favorite types of books and report frequencies or relative frequencies in a bar graph of people liking mysteries, adventure stories, science fiction, and so on.
Once a statistical question has been posed and relevant data types identified, the next step of an investigation is collecting data cases to study. The topic of sampling is addressed in the Grade 7 Unit Samples and Populations. The essential idea behind sampling is to gain information about a whole population by analyzing only a part of the population. A census collects data from the entire population whose attributes are being studied. Generally, conducting a census is not possible or reasonable because of such factors as cost and the size of the population. Hence, there is a need to collect samples of data and use the data from the samples to make predictions about populations.
A central issue in sampling is the need for representative samples. To ensure representative samples, we try to select random samples. A number of strategies for making random choices, such as drawing names from a hat, spinning spinners, tossing number cubes, and generating lists of values using a calculator or computer, are developed earlier in What Do You Expect? These strategies are used later in Samples and Populations. Students realize that there is an equally likely chance for any number to be generated by any spin, toss, or key press. In Samples and Populations, students realize that these numbers may be used to select members of a population to be part of a sample. In other words, there is an equally likely chance for any member of a population to be included in the sample when samples are chosen randomly.
In Samples and Populations, students develop a sound, general sense about what makes a good sample size. Even with a random sampling strategy, descriptive statistics such as means and medians of the samples will vary from one sample to another. The potential accuracy of a sample statistic (i.e., as a predictor of the population statistic) improves with the size of the sample. As a rule of thumb, sample sizes of 25 to 30 are appropriate for most of the problems that students encounter at this level.
Sample data might be numerical or categorical, univariate or bivariate. Knowing the type of data helps us to determine the most appropriate measures of center and variability, and make choices of representations.
Analyzing Distributions
The primary purpose of statistical analysis is to provide an accounting of the variability in collected data. In order to do this, it is generally very helpful to display and examine patterns in the distribution of data values. The distribution of data refers to the way data occur in a data set, necessitating a focus on aggregate features of data sets. When students work with data, they are often interested in the individual cases. However, statisticians like to look at the overall distribution of a data set. Distributions, unlike individual cases, have properties such as measures of central tendency (i.e., mean, median, mode) or spread (e.g., outliers, range, interquartile range, mean absolute deviation) or shape (e.g., clumps, gaps, symmetric, skewed).
Designing representations
The graphs addressed in CMP3 serve three different purposes. First, there are graphs that summarize frequencies of occurrence of individual cases of data values, such as line plots, dot plots, and frequency bar graphs. Second, graphs can also be used to group cases in intervals. This is useful when there is greater variability in spread and/or few data values are identical so tallying frequencies is not helpful. The two graphs used that group cases in intervals are histograms and box-and-whisker plots (also called box plots). These graphs are discussed in Data About Us and Samples and Populations. Finally, in Thinking With Mathematical Models, coordinate graphs, like scatter plots, are used to show association between paired numerical variables.
Statistical graphs model real-world situations and facilitate analysis. Students have to select an appropriate type of graph model, label with appropriate units for the quantities under examination, and summarize with useful levels of accuracy. These ideas are part of a broad modeling strand, which gets explicit mention in the CCSSM for High School.
An important attribute of a graph is its shape. The shape of the graph may help answer such questions as:
- Which data values or intervals of values occur most frequently?
- Are there gaps in the data?
- Are there unusual data values or outliers?
- What data values or intervals of data appear to be typical?
- How can we describe the variability among the data values?
- Are there more data values at one end of the graph than at the other end?
- Do the variables appear to be related or not (bivariate data)?
Some of these questions can be answered with numerical measures, as well as with general observations based on looking at the graph of a distribution.
Measures of Center and Variability
There are several numerical measures of center or spread that are used to summarize distributions. These are essential tools in statistics. In CMP, students learn about three measures of central tendency: mode, median, and mean. Consider these data:
| Name | Number of People in Household |
|---|---|
| Ollie | 2 |
| Yarnell | 3 |
| Gary | 3 |
| Ruth | 4 |
| Paul | 6 |
| Brenda | 6 |
- In these data, there are two such values (3 and 6), so we say the distribution is bimodal. A distribution may be unimodal, bimodal, or multimodal.
- The median marks the location that divides a distribution into two equal parts. In these data, the median is 31⁄2 people.
- The mean is 4 people.
There are three interpretations of mean (or average) used in CMP.
- The fair share or evening out interpretation is looking at the data value that would occur if everyone received the same amount. This is the model emphasized in grades 6-8.
- The balance model is when differences from the mean “balance out” so that the sum of differences below and above the mean equal 0. This model is hinted at when students work with the MAD (mean absolute deviation) in Data About Us and Samples and Populations.
- The typical value is a general interpretation used more casually when students are being asked to think about the three measures of center and which to use.
It is important that students learn to make choices about which measure of center to choose to summarize for a distribution. Sometimes the choice is clear: the mean and median cannot be used with categorical data. Mode may be used with both categorical and numerical data. Sometimes the choice is less clear and students have to use their best judgment as to which measure provides a good description of what is typical of a distribution. The median is not influenced by values at the extremes of a distribution and so might be chosen if we do not want extremes to influence what is considered typical. The mean incorporates all values in a distribution and so is influenced by values at the extremes of a distribution. If we want these to influence what is considered typical we choose the mean.
In Thinking With Mathematical Models, students are introduced to a new idea related to judging what is typical of a distribution: a line of best fit. Since each data point in a scatter plot has two variables, and the question is whether these variables relate to each other or not, the distribution may be summarized by a line, not a single numerical value. When it is appropriate to draw a line of best fit, the line passes among the points making an overall trend visible. Technically the line of best fit is influenced by all the points, including those that are very atypical of the trend. In Thinking With Mathematical Models, students choose whether a line of best fit is an appropriate model. If it is, they can use their understanding of linearity to draw the line and use its equation to predict data values within or beyond the collected data.
In Data About Us and Samples and Populations students are introduced to several measures of variability. Variability is a quantitative measure of how close together— or spread out—a distribution of measures or counts from some group of “things” are. Several questions may be used to highlight interesting aspects of variation.
- What does a distribution look like?
- How much do the data points vary from one another or from the mean or median?
- What are possible reasons why there is variation in these data?
As with measures of center, it is just as important for students to develop the judgment skills to choose among measures of variability as it is for them to be able to compute the measures. Again, there are constraints on the choices.
In the Grade 6 Unit Data About Us , students use range, the difference between the maximum and the minimum data values, as one measure of spread. In addition, students are encouraged to talk about where data cluster and where there are “holes” in the data as further ways to comment about spread and variability. The range is obviously influenced by extreme values or outliers; it may suggest a higher variability than warranted in describing a distribution.
Statisticians often want to compare how data vary in relation to a measure of central tendency, either the median or the mean. Two measures of variation, interquartile range and mean absolute deviation, are introduced in Data About Us. The interquartile range (IQR) is only used with the median. It is the range of the middle 50% of the data values. The IQR does not reflect the presence of any unusual values or outliers. It provides a numerical measure of the spread of the data values between the first and third quartiles of a distribution. The size of the IQR provides information about how concentrated or spread out the middle 50% of the data are. The mean absolute deviation (MAD) connects the mean with a measure of spread. In some data sets, the data values are concentrated close to the mean. In other data sets, the data values are more widely spread out around the mean. The MAD is a number that is computed using the differences of data values from their mean. The MAD is the average distance between each data value and the mean, and is therefore only used in conjunction with the mean.
In Samples and Populations students learn to use the means and MADs, or medians and IQRs, of two samples to compare how similar or dissimilar the samples are. Similarity might indicate that the samples were chosen from a similar population; dissimilarity might indicate that they were chosen from different underlying populations.
In Thinking With Mathematical Models, a fourth measure of variability, the standard deviation, is introduced. This measure is another way to connect the mean with a measure of spread. It is similar in interpretation and use to the MAD but its computation is slightly different.
With bivariate data, students cannot use the same measures of center and spread as for univariate data. We have seen above that, analogous to a measure of center being used to describe a distribution with a single number, a line of best fit can summarize bivariate data in a scatter plot with a single trend line. When statisticians suspect that the values of two different attributes are related in meaningful ways, they often measure the strength of the relationship using a statistic called the correlation coefficient. The correlation coefficient is a number between 1 and - 1 that tells how close the pattern of data points is to a straight line. The correlation coefficient is a measure of linear association. A value of r, the correlation coefficient, close to - 1 or 1 indicates the data points are clustered closely around a line of best fit, and there is a strong association between variables. This is analogous to a low measure of spread for one-variable data. A value of r close to zero indicates the data points are not clustered closely around a line of best fit, and there is no association between variables. The value of r is calculated by finding the distance between each point in the scatter plot from the line of best fit. These distances are called residuals. Visually, residuals recall the calculation of MAD, measuring distances of univariate data from the mean.
In Thinking With Mathematical Models, students are asked to explore associations between different categorical variables by arranging categorical frequency data in two-way tables. For example, to see whether employment outside of school hours affects student performance on homework tasks, data about four kinds of students are arranged in the following table:
| After School Job | No After School Job | Totals | |
|---|---|---|---|
| On-Time Homework | 8 | 25 | 33 |
| Missing Homework | 12 | 15 | 27 |
| Totals | 20 | 40 | 60 |
Interpreting Results
The final critical stage of any statistical investigation is interpreting the results of data collection and analysis to answer the question that prompted work in the first place. In all the Data Units students are asked to report their findings. These reports may be descriptive or predictive. Interpretations are made, allowing for the variability in the data. This generally means describing and/or comparing data distributions by referring to the following things:
- Measures of center
- Measures of variation
- Salient features of the shape of distributions like symmetry and skewness
- Unusual features like gaps, clusters, and outliers
- Patterns of association between pairs of attributes measured by correlations, residuals for linear models, and proportions of entries in two-way tables
Each of these ideas is developed in a primary statistics Unit. But there are also many significant connections in other Units that deal with fractions, decimals, percents, and ratios, and with the algebra of linear functions and equations.
Conclusion
By the completion of all primary and supporting Units for the statistics strand of CMP3, students will have mastered all of the content standards of the CCSSM in statistics and data analysis and will be well prepared for more sophisticated study in high school mathematics. Students will also develop a strong disposition to look for data supporting claims in other disciplines and in public life and students can apply insightful analysis to those data.
Probability
Propositions in the logical form “If A then B” are at the heart of mathematics. In algebra, we solve equations to show things like, “If 7x + 5 = 47, then x = 6.” In geometry, we prove things like, “If the sides of a triangle are in the ratio 3:4:5, then it is a right triangle.” However, in many important quantitative reasoning tasks there is uncertainty in the If, then inferences that can be made. For example, outcomes in a game of chance can at best be assigned probabilities of occurrence. Outcomes of medical tests and predicted effects of treatments can be given only with caveats involving probabilities.
The theory of probability has developed to give the best possible mathematical reasoning about questions involving chance and uncertainty. Since outcomes of so many events in science, engineering, and daily life are predictable only by probabilistic claims, the study of probability has become an important strand in school and collegiate mathematics.
The CCSSM content standards for grades 6–8 specify probability goals only in Grade 7. Thus, there is one primary Unit at Grade 7, What Do You Expect?, that deals with all of these standards. However, there are significant connections to those topics in many other Units. Because of the heavy emphasis on number and operations before Grade 7, CMP students should be well prepared for the work with fractions, decimals, percents, and ratios that is essential in probability.
What Do You Expect? aims to develop student ability to do the following:
- Identify problem situations involving random variation and correctly interpret probability statements about uncertain outcomes in such cases
- Use experimental and simulation methods to estimate probabilities for activities with uncertain outcomes
- Use theoretical probability reasoning to calculate probabilities of simple and compound events
- Calculate and interpret expected values of simple random variables
These objectives and their connections to other content in the number, geometry, data analysis, and algebra strands are elaborated upon in the following sections.
Randomness The word random is often used to mean “haphazard” and “completely unpredictable.” In probability, use of the word random to describe outcomes of an activity means that the result of any single trial is unpredictable, but the pattern of outcomes from many repeated trials is fairly predictable. For example, tossing a coin is an activity with random outcomes, because the result of any particular toss cannot be predicted with any confidence. But, in the long run, you will have close to 50% heads and 50% tails. Similarly, the number of boys (or girls) in a three-child family is a random variable. Any specific three-child family might have zero boys, one boy, two boys, or three boys. But the proportion of many such families that have no boys will be close to 1/8, the proportion that will have 1 boy will be close to 3/8, and so on.
To draw correct inferences from information about probabilities, one has to appreciate the meaning of probability statements as predictions of the long-term patterns in outcomes from activities that exhibit randomness. Probabilities are numbers from 0 to 1, with a probability of 0 indicating impossible outcomes, a probability of 1 indicating certain outcomes, and probabilities between 0 and 1 indicating varying degrees of outcome likelihood. The probability fractions are statements about the proportion of outcomes from an activity that can be expected to occur in many trials of that activity. For example, the probability of getting 2 heads in 2 tosses of a fair coin is 0.25 because one would expect in many tosses of two coins that about one-quarter of the results would show heads on both.
Randomness also plays a role in Samples and Populations. Students realize that if sample outcomes are to be used to predict statistics about an underlying population, then it would be optimal if the sample were unbiased and representative of the population. One way to choose a sample that is free from bias is to use a tool that will select members randomly. Samples chosen this way will vary in their makeup, and each individual sample distribution may or may not resemble the population distribution. However, if many random samples are drawn, the distribution of sample means will cluster closely around the mean of the population. Thus, for any individual random sample of a particular size, we can calculate the probability that predictions about the population will be accurate. This calculation is beyond the scope of the Data strand in CMP but lies at the heart of using samples to make predictions about populations.
What Do You Expect? includes many problems that engage students in developing and interpreting probability statements about activities with random outcomes. The activities include games, hands-on experiments, and thought experiments.
Experimental Probability
Any probability statement is a prediction, in the face of uncertainty, about the likelihood of different outcomes from an activity involving randomness. One natural way to develop probability estimates for specific outcomes of experiments, games, and other activities is to simply perform the activity repeatedly, keep track of the results, and use the fraction number of favorable outcomes/number of trails as an experimental probability estimate. Experimental data gathered over many trials should produce probabilities that are close to the theoretical probabilities. This idea is sometimes called the Law of Large Numbers. The Law of Large Numbers does not say that you should expect exactly 50% heads in any given large number of trials. Instead, it says that as the number of trials gets larger, you expect the percent of heads to be around 50%. For 1 million tosses, exactly 50% (500,000) heads is improbable. But for 1 million tosses, it would be extremely unlikely for the percent of heads to be less than 49% or more than 51%.
Coin tossing is one of the most common activities for illustrating an experimental approach to probability. However, most students will have intuitive sense about the outcomes that can be expected from coin tossing. Experimental methods are particularly useful and convincing when the challenge is to estimate probabilities for which there is no natural or intuitive number to guess. For example, if one tosses a common thumbtack on a hard flat surface, it can land in one of two conceivable positions—point down or point up (on its head). But the probability of each outcome is not immediately obvious (in fact, it depends on the size of the tack head and the length of the spike). What Do You Expect? includes several such non-intuitive activities to highlight the ideas and virtues of experimental approaches to probability.
A common and productive variation on experimental derivation of probability estimates is through simulation. A simulation is an experiment that has the same mathematical structure as an activity or experiment of interest, but is easier to actually perform. For example, if you don’t have the patience to actually toss a coin hundreds of times, you could use a calculator random number generator to produce a sequence of single-digit numbers where you count each odd number outcome as a “head” and each even number outcome as a “tail.”
Coin tossing itself can be used to simulate other activities that are difficult to repeat many times. Assuming equal probabilities for girl and boy births, you could simulate the births in three-child families by tossing three fair coins and observing the outcomes—tails for boys and heads for girls. You could repeat the coin toss often and record the numbers of boys and girls in each family. Then, you could use the frequencies of each number (0, 1, 2, or 3) divided by the number of families simulated to estimate probabilities of different numbers of boys or girls.
Experimental and simulation methods for estimating probabilities are very powerful tools, especially with access to calculating and computing technology. In addition to learning very useful probability reasoning tools, this experimental side of the subject provides continual reinforcement of the fundamental idea that probabilities are statements about the long-term results of repeated activities in which outcomes of individual trials are very hard to predict.
Theoretical Probability
In quite a few probability situations, there is a natural or logical way to assign probabilities to simple outcomes of activities, but the question of interest asks about probabilities of compound outcomes (often referred to as events). For example, returning to the questions about likelihood of different numbers of boys and girls in three-child families, it is reasonable to assume that the boy and girl births are equally likely. The sample space or outcome set for the experiment of having a three- child family can be represented by a collection of eight different chains of B and G symbols like this: {BBB, BBG, BGB, GBB, GGB, GBG, BGG, GGG}. Each individual family pattern is as likely as the others, so one can reason that each possibility has probability1/8. This result of reasoning alone is called a theoretical probability.
Theoretical probabilities, such as the probability of birth order boy-boy-girl, can be used to derive probabilities of further compound events, such as the likelihood of having exactly 2 boys in a three-child family (3/8) or the likelihood of having at most 1 boy in a three-child family (4/8). This kind of reasoning about probabilities by thought experiments illustrates the natural principle that the probability of any event is the sum of the probabilities of its disjoint outcomes. (The sum of the probabilities of BBG, BGB, GBB is 3/8. The sum of the probabilities of GGG, GGB, GBG, BGG is 4/8.) This principle and the assignment of probabilities by theoretical reasoning in general are illustrated in many Problems of What Do You Expect?
The power of theoretical probability reasoning can often be applied to save the toil of deriving probabilities by experimental or simulation methods. For example, suppose that a game spinner has the sectors shown in the following diagram.
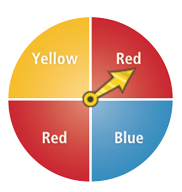
In this case, it makes sense to use areas or central angles of the four sectors to derive theoretical probabilities of the outcomes Red (1 /2), Blue (1 /4), and Yellow ( 1 /4). Then, further reasoning implies that the P(Red or Blue) = (3 /4), P(not Red) = (1 /2), and so on.
Theoretical probabilities can utilize area models in another very powerful way. Suppose that on average a basketball player makes 60% of her free throws. You can show 60% as shown on the diagram below. If you then want to know the probability of making the first two free throws, you can shade 60% vertically on top of the first diagram to end up with the second diagram. There are four disjoint outcomes of this compound event, represented by four areas. The probabilities of making 0 (16%),1 (48%), or 2 (36%) free throws are shown on the second diagram. (Of course, if the second part of the event is dependent on the first, and no second free throw is taken if the first is missed, then the probability of making 0 free throws is 40%, the probability of making 1 free throw, the first only, is 24%, and the probability of making 2 free throws is 36%.)
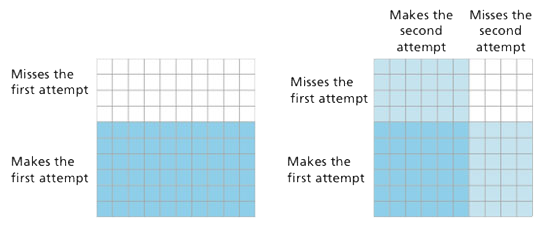
Several problems in What Do You Expect? develop student understanding and skill use of this sort of visual and theoretical probability reasoning. Modeling multiplicative situations with areas is used in several strands in CMP, from multiplication of fractions in Let’s Be Rational, to the Distributive Property in Prime Time or Frogs, Fleas and Painted Cubes, to computation of probabilities of compound events in What Do You Expect?, to illustrating completing the square in Function Junction. CMP makes careful, strategic use of models throughout the curriculum.
While theoretical calculation of probabilities is often more efficient than experimental and simulation approaches, it depends on making correct assumptions about?the random activity that is being analyzed by thought experiments. Furthermore, reliance on theoretical probability reasoning alone runs the risk of giving students the impression that probabilities are in fact exact predictions of individual trials, not statements about approximate long-term relative frequencies of various possible simple and compound events. Thus, the combination of experimental and theoretical probability problems in this Unit is essential.
Expected Value
In financial investments and games of chance, probability is related to resulting returns. When probabilities of individual outcomes are combined with numerical payoffs for each, the result is the expected value of the game or experiment or activity. For example, suppose that data is collected about some students competing in a basketball game that gives each of them throws at three different points on the court. Points are assigned to reflect the difficulty of making the throw. The probabilities have been found by performing an experiment and collecting data.
| Throw Distance | Point Payoff | Kyla's Probability of Making the Throw |
|---|---|---|
| 5 | 1 | .08 |
| 10 | 3 | 0.6 |
| 20 | 5 | 0.2 |
What score should Kyla expect in each play of the game? The calculation of expected value multiplies each payoff by the probability of that outcome and sums the products. In this case, the expected value is 1(0.8) + 3(0.6) + 5(0.2) = 3.6.
Conclusion
What Do You Expect? develops all of the probability concepts and procedural skills specified in the content standards of the CCSSM with a consistent focus on meaningful derivations of ideas, techniques, and applications. When students complete the Unit and make the important connections in other content strands, they should be well on their way to developing understanding skills required for reasoning under conditions of uncertainty.